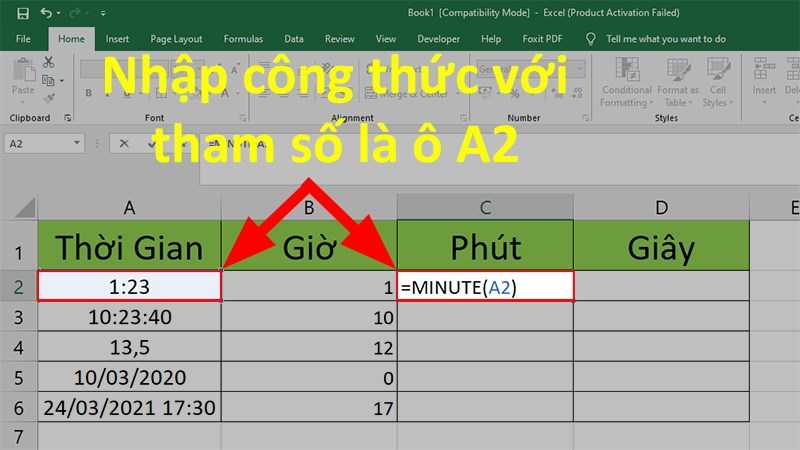
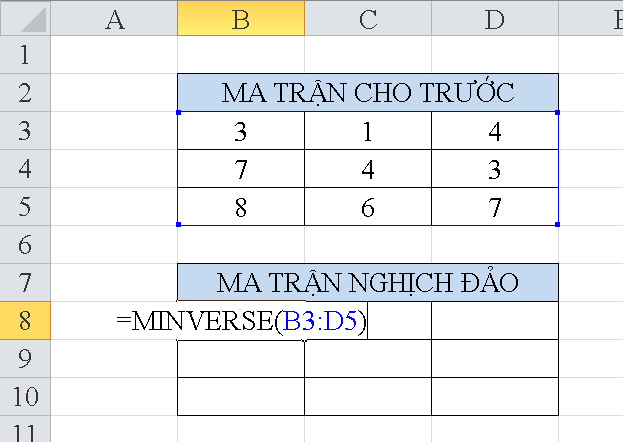
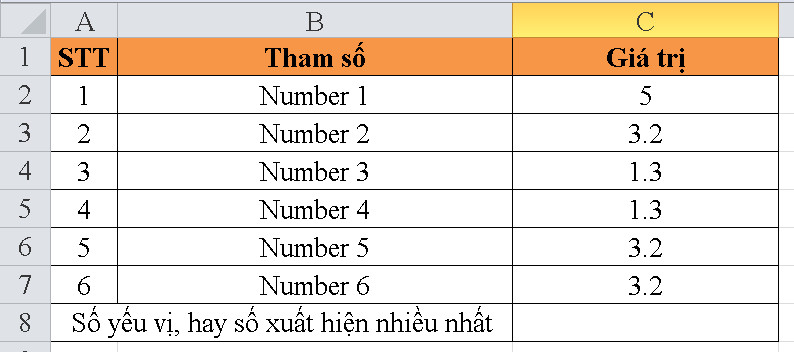
Bạn đã bao giờ tìm hiểu về cú pháp và chức năng của các hàm thống kê trong Excel chưa? Như bạn biết, Excel cung cấp một nhóm các hàm thống kê mạnh mẽ giúp tính toán và phân tích dữ liệu một cách hiệu quả.
Từ hàm SUM để tính tổng đến hàm COUNT để đếm số lượng các giá trị trong một phạm vi, mỗi hàm có một cú pháp riêng và chức năng đặc biệt. Tham khảo aptech và những thông tin sau sẽ giúp bạn thao tác với dữ liệu một cách chính xác và nhanh chóng trong Excel.

1. Bộ sưu tập các hàm có chức năng về xử lý số liệu thống kê.
- Hàm AVEDEV (Average Absolute Deviation) được sử dụng để đo độ biến thiên của tập dữ liệu. Nó tính trung bình của các giá trị tuyệt đối của sự chênh lệch giữa mỗi điểm dữ liệu và giá trị trung bình của tập dữ liệu. Hàm này giúp đánh giá mức độ phân tán của dữ liệu xung quanh giá trị trung bình và thể hiện độ lệch tuyệt đối trung bình.
- Cú pháp của hàm AVEDEV trong Excel (hoặc các ứng dụng tương tự) là như sau:
AVEDEV(number1, [number2], …)
Trong đó:
– `number1` là bắt buộc, đây là giá trị đầu tiên mà bạn muốn tính trung bình độ lệch tuyệt đối của chúng.
– `number2`, `number3`, … là các giá trị khác, tùy chọn, mà bạn muốn tính trung bình độ lệch tuyệt đối của chúng.
Bạn có thể cung cấp từ 1 đến 255 đối số cho hàm AVEDEV. Bạn cũng có thể sử dụng một mảng (array) đơn hoặc tham chiếu đến một mảng thay vì liệt kê từng giá trị cụ thể, bằng cách phân tách các giá trị bằng dấu phẩy.
Ví dụ:
– `AVEDEV(A1, A2, A3)` tính trung bình độ lệch tuyệt đối của các giá trị A1, A2 và A3.
– `AVEDEV(B1:B10)` tính trung bình độ lệch tuyệt đối của các giá trị trong dãy từ ô B1 đến B10.
– `AVEDEV(1, 2, 3, 4, 5)` tính trung bình độ lệch tuyệt đối của các giá trị 1, 2, 3, 4 và 5.
Lưu ý rằng hàm AVEDEV sẽ trả về giá trị số, thể hiện trung bình độ lệch tuyệt đối của các giá trị mà bạn đã cung cấp.
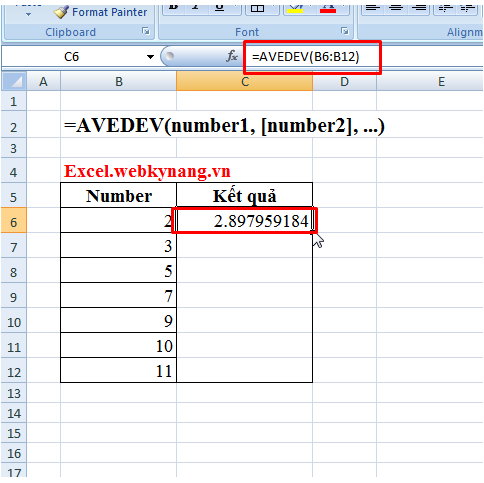
- Hàm AVERAGIFS trong Excel (hoặc các ứng dụng tương tự) được sử dụng để tính giá trị trung bình của các giá trị trong một khoảng (range) dựa trên các điều kiện chỉ định trước. Cú pháp của hàm này như sau:
AVERAGIFS(average_range, criteria_range1, criteria1, [criteria_range2, criteria2], …)
Trong đó:
– `average_range` là khoảng (range) chứa các giá trị mà bạn muốn tính trung bình.
– `criteria_range1` là khoảng (range) chứa các giá trị mà bạn muốn kiểm tra điều kiện.
– `criteria1` là điều kiện mà bạn muốn áp dụng cho `criteria_range1`.
– `criteria_range2`, `criteria2`, … là các khoảng (range) và điều kiện tương ứng khác (tùy chọn). Bạn có thể chỉ định nhiều điều kiện hơn bằng cách cung cấp thêm cặp `criteria_range` và `criteria`.
Hàm AVERAGIFS sẽ tính trung bình các giá trị trong `average_range` dựa trên các điều kiện được chỉ định trong `criteria_range` và `criteria`. Chỉ có các giá trị thỏa mãn tất cả các điều kiện mới được tính vào trung bình.
Ví dụ:
– `AVERAGIFS(B2:B10, A2:A10, “Apple”)` tính trung bình các giá trị trong khoảng B2:B10 nếu tương ứng trong khoảng A2:A10 là “Apple”.
– `AVERAGIFS(C2:C20, A2:A20, “Banana”, B2:B20, “High”)` tính trung bình các giá trị trong khoảng C2:C20 nếu tương ứng trong khoảng A2:A20 là “Banana” và tương ứng trong khoảng B2:B20 là “High”.
Hàm AVERAGIFS giúp bạn tính trung bình theo nhiều điều kiện khác nhau, giúp phân tích dữ liệu dễ dàng hơn.
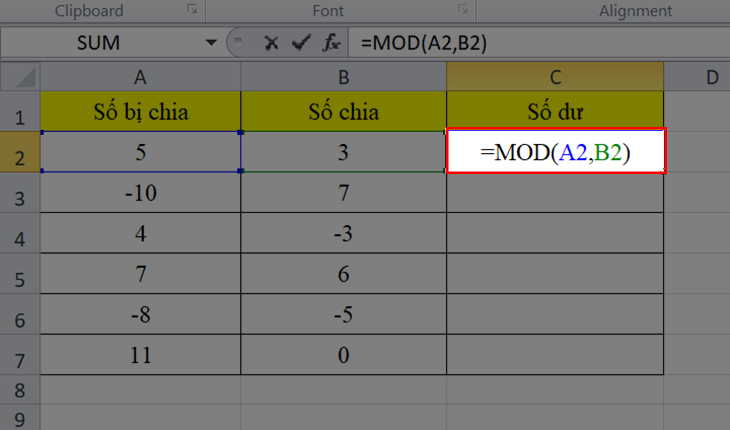
- Hàm COUNT trong Excel (hoặc các ứng dụng tương tự) được sử dụng để đếm số lượng ô chứa giá trị số trong danh sách các đối số. Cú pháp của hàm này như sau:
COUNT(value1, value2, …)
Trong đó:
– `value1`, `value2`, … là các đối số mà bạn muốn đếm số lượng ô chứa giá trị số.
Hàm COUNT sẽ trả về số lượng ô trong danh sách các đối số mà chứa giá trị số (không phải văn bản hoặc giá trị rỗng).
Ví dụ:
– `COUNT(A1, A2, A3, A4)` đếm số lượng ô trong các ô A1, A2, A3, A4 mà chứa giá trị số.
– `COUNT(B1:B10)` đếm số lượng ô trong dãy từ B1 đến B10 mà chứa giá trị số.
– `COUNT(1, 2, 3, 4, 5)` đếm số lượng số trong danh sách các giá trị 1, 2, 3, 4, 5.
Hàm COUNT thường được sử dụng để thống kê số lượng dữ liệu số trong các phân tích và báo cáo.
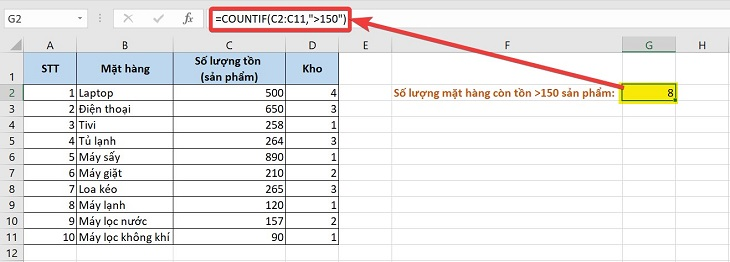
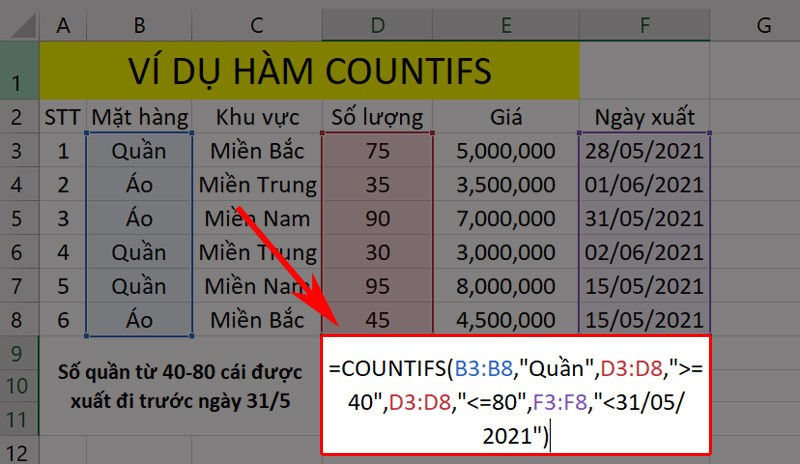
- Hàm COUNTIFS trong Excel (hoặc các ứng dụng tương tự) được sử dụng để đếm số lượng ô trong một khoảng (range) cùng thỏa mãn nhiều điều kiện khác nhau. Cú pháp của hàm này như sau:
COUNTIFS(range1, criteria1, [range2, criteria2], …)
Trong đó:
– `range1` là khoảng chứa các giá trị mà bạn muốn kiểm tra điều kiện.
– `criteria1` là điều kiện mà bạn muốn áp dụng cho `range1`.
– `range2`, `criteria2`, … là các khoảng và điều kiện tương ứng khác (tùy chọn). Bạn có thể chỉ định nhiều điều kiện hơn bằng cách cung cấp thêm cặp `range` và `criteria`.
Hàm COUNTIFS sẽ đếm số lượng ô trong `range1` mà cùng thỏa mãn tất cả các điều kiện đã được chỉ định. Chỉ có các ô thỏa mãn tất cả các điều kiện mới được đếm.
Ví dụ:
– `COUNTIFS(A2:A10, “Apple”)` đếm số lượng ô trong khoảng A2:A10 mà chứa giá trị “Apple”.
– `COUNTIFS(A2:A20, “Banana”, B2:B20, “High”)` đếm số lượng ô trong khoảng A2:A20 mà chứa giá trị “Banana” và tương ứng trong khoảng B2:B20 là “High”.
Hàm COUNTIFS giúp bạn thống kê số lượng dữ liệu theo nhiều điều kiện khác nhau, giúp phân tích dữ liệu dễ dàng hơn.
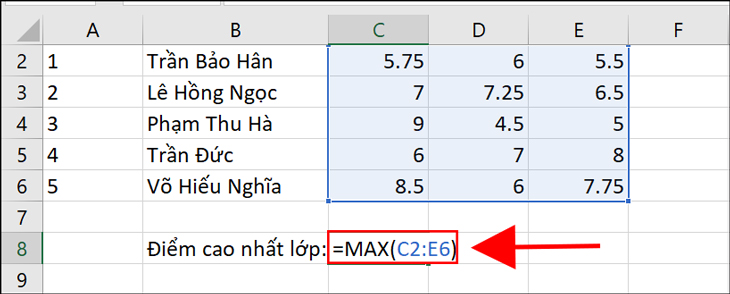
- Hàm MAX trong Excel (hoặc các ứng dụng tương tự). Hàm MAX được sử dụng để trả về giá trị lớn nhất trong một danh sách các đối số hoặc phạm vi dữ liệu.
Cú pháp của hàm MAX như sau:
MAX(number1, number2, …)
Trong đó:
– `number1`, `number2`, … là các giá trị hoặc đối số mà bạn muốn tìm giá trị lớn nhất trong đó.
Ví dụ:
– `MAX(A1, A2, A3)` trả về giá trị lớn nhất trong các ô A1, A2 và A3.
– `MAX(B1:B10)` trả về giá trị lớn nhất trong dãy từ ô B1 đến B10.
– `MAX(5, 2, 9, 1, 7)` trả về giá trị lớn nhất trong các giá trị 5, 2, 9, 1 và 7.
Hàm MAX là một công cụ hữu ích để tìm giá trị cao nhất trong một tập hợp dữ liệu và có thể được sử dụng trong các tính toán và phân tích dữ liệu khác nhau.
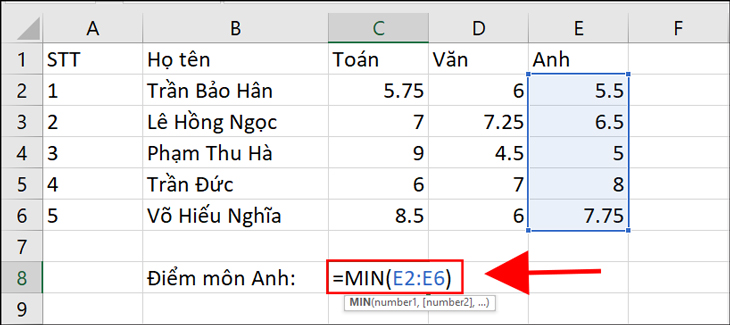
- Hàm MIN trong Excel (hoặc các ứng dụng tương tự). Hàm MIN được sử dụng để trả về giá trị nhỏ nhất trong một tập hợp các đối số số.
Cú pháp của hàm MIN như sau:
MIN(number1, number2, …)
Trong đó:
– `number1`, `number2`, … là các giá trị hoặc đối số mà bạn muốn tìm giá trị nhỏ nhất trong đó.
Ví dụ:
– `MIN(A1, A2, A3)` trả về giá trị nhỏ nhất trong các ô A1, A2 và A3.
– `MIN(B1:B10)` trả về giá trị nhỏ nhất trong dãy từ ô B1 đến B10.
– `MIN(5, 2, 9, 1, 7)` trả về giá trị nhỏ nhất trong các giá trị 5, 2, 9, 1 và 7.
Hàm MIN là một công cụ hữu ích để tìm giá trị nhỏ nhất trong một tập hợp dữ liệu và có thể được sử dụng trong các tính toán và phân tích dữ liệu khác nhau.
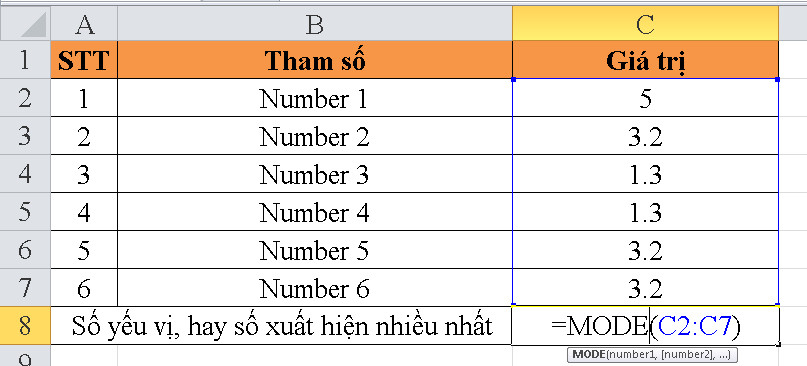
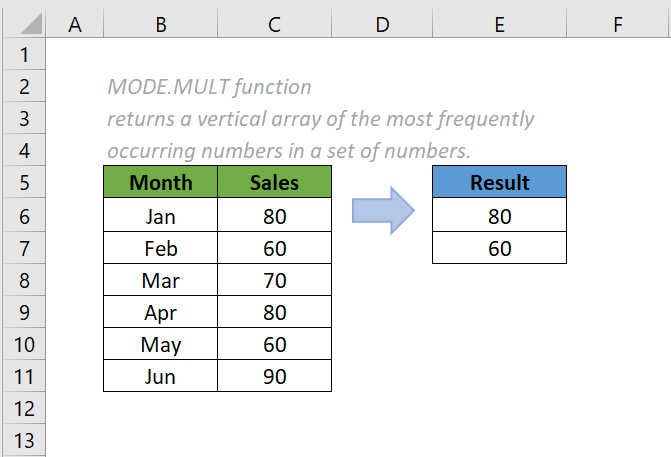
- Hàm MODE trong Excel (hoặc các ứng dụng tương tự). Hàm MODE được sử dụng để trả về giá trị xuất hiện thường xuyên lặp lại nhất trong một tập hợp các đối số số.
Cú pháp của hàm MODE như sau:
MODE(number1, number2, …)
Trong đó:
– `number1`, `number2`, … là các giá trị hoặc đối số mà bạn muốn tìm giá trị xuất hiện thường xuyên lặp lại nhất.
Ví dụ:
– `MODE(A1:A10)` trả về giá trị xuất hiện thường xuyên lặp lại nhất trong dãy từ ô A1 đến A10.
– `MODE(2, 3, 4, 4, 5, 5, 5, 6, 6, 7)` trả về giá trị xuất hiện thường xuyên lặp lại nhất trong tập hợp các giá trị.
Lưu ý rằng hàm MODE có thể trả về nhiều giá trị nếu có nhiều giá trị có tần suất xuất hiện lớn nhất. Nó là một công cụ hữu ích trong việc phân tích phân phối tần suất của dữ liệu.
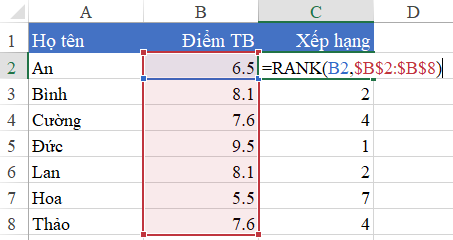
- Hàm RANK trong Excel (hoặc các ứng dụng tương tự). Hàm RANK được sử dụng để trả về thứ hạng của một số trong một danh sách các số.
Cú pháp của hàm RANK như sau:
RANK(number, ref, order)
Trong đó:
– `number` là số mà bạn muốn tìm thứ hạng của.
– `ref` là khoảng (range) chứa danh sách các số mà bạn muốn tìm thứ hạng trong đó.
– `order` là tham số tùy chọn xác định cách thứ hạng được tính toán. Nếu bạn để `order` là 0 hoặc bỏ trống, thứ hạng lớn nhất tương ứng với thứ hạng 1, thứ hạng thấp nhất tương ứng với thứ hạng cao nhất. Nếu bạn đặt `order` là 1, thứ hạng lớn nhất tương ứng với thứ hạng cao nhất, thứ hạng thấp nhất tương ứng với thứ hạng 1.
Ví dụ:
– `RANK(A1, A2:A10, 0)` trả về thứ hạng của giá trị trong ô A1 trong dãy từ A2 đến A10 với thứ hạng lớn nhất tương ứng với thứ hạng 1.
– `RANK(500, B1:B20, 1)` trả về thứ hạng của số 500 trong dãy từ B1 đến B20 với thứ hạng lớn nhất tương ứng với thứ hạng 1.
Hàm RANK là một công cụ hữu ích trong việc xếp hạng và so sánh các giá trị trong một danh sách.
2. Bộ các hàm liên quan đến Xác suất phân phối.
- Hàm LOGINV
Hàm LOGINV là một hàm trong ngôn ngữ lập trình thống kê, được sử dụng để tính giá trị nghịch đảo của hàm phân phối logarit chuẩn tích lũy. Phân phối logarit chuẩn là một biến thể của phân phối chuẩn trong đó logarit tự nhiên của biến ngẫu nhiên có phân phối chuẩn với các tham số trung bình (mean) và độ lệch chuẩn (standard deviation).
Công thức toán học của hàm LOGINV có thể được biểu diễn như sau:
$$text{LOGINV}(probability, mean, standard_dev)$$
Trong đó:
– **probability**: Xác suất tích lũy mà bạn muốn tìm giá trị nghịch đảo.
– **mean**: Trung bình của phân phối logarit chuẩn.
– **standard_dev**: Độ lệch chuẩn của phân phối logarit chuẩn.
Hàm LOGINV thường được sử dụng để tính giá trị nghịch đảo của một xác suất tích lũy cụ thể trong phân phối logarit chuẩn. Điều này có thể hữu ích trong việc dự đoán giá trị ngẫu nhiên ban đầu dựa trên xác suất đã cho.
Ví dụ, nếu bạn muốn tìm giá trị nghịch đảo của xác suất tích lũy 0.8 trong phân phối logarit chuẩn với trung bình 1.5 và độ lệch chuẩn 0.2, bạn có thể sử dụng hàm LOGINV như sau:
$$text{LOGINV}(0.8, 1.5, 0.2)$$
Hàm này sẽ trả về giá trị nghịch đảo tương ứng với xác suất tích lũy là 0.8 trong phân phối logarit chuẩn.

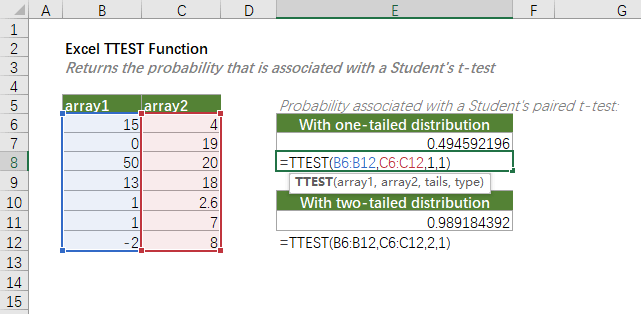
- Hàm TTEST
Hàm TTEST là một hàm trong ngôn ngữ lập trình thống kê, thường được sử dụng để thực hiện phép thử t Student giữa hai tập hợp dữ liệu để xác định xem chúng có xuất phát từ hai tập hợp gốc có cùng giá trị trung bình hay không. Phép thử t Student thường được sử dụng để so sánh giá trị trung bình của hai tập hợp dữ liệu và đưa ra kết luận về sự khác biệt có ý nghĩa thống kê giữa chúng.
Công thức toán học của hàm TTEST có thể được biểu diễn như sau:
$$text{TTEST}(array1, array2, tails, type)$$
Trong đó:
– **array1**: Mảng dữ liệu của tập hợp thứ nhất.
– **array2**: Mảng dữ liệu của tập hợp thứ hai.
– **tails**: Số lượng đuôi của phép thử. Nó xác định xem bạn đang thực hiện phép thử hai đuôi (two-tailed) hay một đuôi (one-tailed). Nếu là two-tailed, xác suất sẽ được chia đôi. Nếu là one-tailed, bạn cần xác định hướng so sánh (lớn hơn hoặc nhỏ hơn).
– **type**: Loại phép thử. Có thể là “1” (phép thử đối nhất) hoặc “2” (phép thử độc lập).
Kết quả của hàm TTEST thường là xác suất kết hợp (p-value), một giá trị xác suất thể hiện xác suất của sự khác biệt mà bạn quan sát được giữa hai tập hợp dữ liệu nếu giả định rằng giá trị trung bình thực sự bằng nhau.
Ví dụ, nếu bạn muốn thực hiện phép thử t Student giữa hai tập hợp dữ liệu “array1” và “array2” để xem xét xem chúng có giá trị trung bình khác nhau hay không, và bạn muốn sử dụng phép thử hai đuôi, bạn có thể sử dụng hàm TTEST như sau:
$$text{TTEST}(array1, array2, 2, 2)$$
Kết quả sẽ là xác suất kết hợp (p-value) mà bạn có thể so sánh với một ngưỡng xác định để đưa ra quyết định về việc chấp nhận hoặc bác bỏ giả thuyết rằng giá trị trung bình của hai tập hợp là bằng nhau.
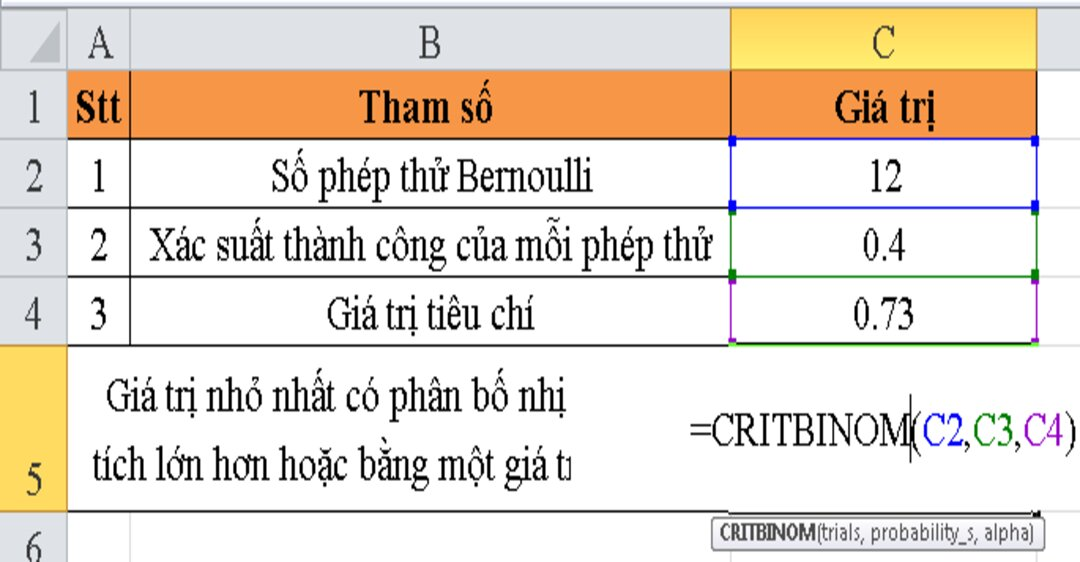
- Hàm CRITBINOM
Hàm CRITBINOM trong ngôn ngữ lập trình thống kê thường được sử dụng để tìm giá trị nhỏ nhất mà phân phối nhị thức tích lũy lớn hơn hoặc bằng một giá trị tiêu chuẩn (thường được ký hiệu là alpha). Phân phối nhị thức là một phân phối xác suất mô tả số lần thành công trong một số lần thử nghiệm độc lập cùng một khả năng thành công. Trong trường hợp của CRITBINOM, bạn đang tìm giá trị nhỏ nhất của số lần thử nghiệm để tổng số lần thành công lớn hơn hoặc bằng giá trị tiêu chuẩn alpha.
Công thức toán học của hàm CRITBINOM có thể được biểu diễn như sau:
$$text{CRITBINOM}(trials, probability_s, alpha)$$
Trong đó:
– **trials**: Số lần thử nghiệm (số lần thử trong phân phối nhị thức).
– **probability_s**: Xác suất thành công trong mỗi lần thử nghiệm.
– **alpha**: Giá trị tiêu chuẩn mà phân phối nhị thức tích lũy cần lớn hơn hoặc bằng.
Hàm này thường được sử dụng trong các ứng dụng kiểm tra chất lượng hoặc quyết định, nơi bạn muốn xác định số lần thử nghiệm cần thiết để đảm bảo xác suất thành công đạt hoặc vượt qua một ngưỡng cụ thể.
Ví dụ, nếu bạn muốn đảm bảo xác suất thành công ít nhất 0.9 trong 10 lần thử nghiệm với xác suất thành công trong mỗi lần thử là 0.2, bạn có thể sử dụng hàm CRITBINOM như sau:
$$text{CRITBINOM}(10, 0.2, 0.9)$$
Hàm này sẽ trả về số lần thử nghiệm cần thiết ít nhất để xác suất thành công tích lũy ít nhất 0.9.
3. Đội hàm liên quan và hồi quy tuyến tính.
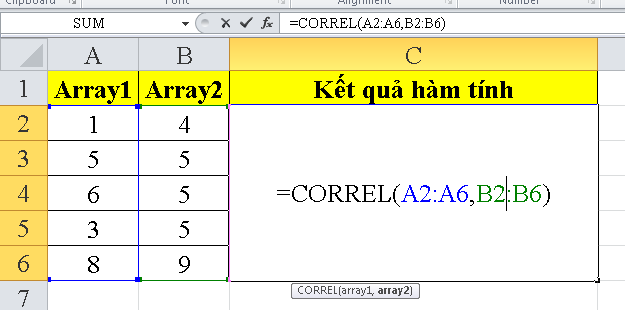
- Hàm CORREL
Hàm CORREL là một hàm trong ngôn ngữ lập trình thống kê, thường được sử dụng để tính hệ số tương quan giữa hai tập hợp dữ liệu. Hệ số tương quan đo lường mức độ mà hai biến có xu hướng biến đổi cùng nhau. Nó là một chỉ số thường được sử dụng để đánh giá mối quan hệ giữa hai thuộc tính hoặc biến.
Công thức toán học của hàm CORREL có thể được biểu diễn như sau:
$$text{CORREL}(array1, array2)$$
Trong đó:
– **array1**: Mảng dữ liệu của thuộc tính hoặc biến thứ nhất.
– **array2**: Mảng dữ liệu của thuộc tính hoặc biến thứ hai.
Kết quả của hàm CORREL thường nằm trong khoảng từ -1 đến 1. Giá trị 1 thể hiện mối quan hệ tuyến tính hoàn toàn thuận lợi giữa hai biến, còn giá trị -1 thể hiện mối quan hệ tuyến tính hoàn toàn nghịch lợi. Giá trị gần 0 thể hiện không có mối quan hệ tuyến tính đáng kể giữa hai biến.
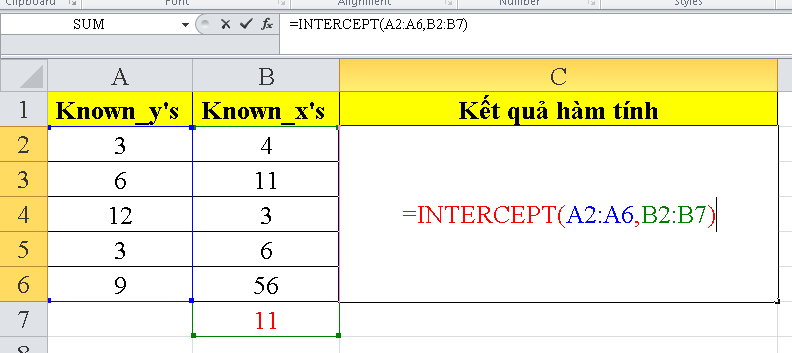
- Hàm INTERCEPT
Hàm INTERCEPT là một hàm trong ngôn ngữ lập trình thống kê và tính toán, thường được sử dụng để tính điểm giao cắt của một đường thẳng với trục y (trục đứng) dựa trên các giá trị x và y hiện có. Điểm giao cắt này thường thể hiện giá trị của biến phụ thuộc khi biến độc lập bằng 0.
Công thức toán học của hàm INTERCEPT có thể được biểu diễn như sau:
$$text{INTERCEPT}(known_y’s, known_x’s)$$
Trong đó:
– **known_y’s**: Mảng các giá trị y đã biết (giá trị của biến phụ thuộc).
– **known_x’s**: Mảng các giá trị x tương ứng đã biết (giá trị của biến độc lập).
Hàm INTERCEPT sử dụng các điểm đã biết để tính toán giá trị của điểm giao cắt của đường thẳng với trục y. Điều này có thể hữu ích trong việc tạo ra mô hình dự đoán dựa trên dữ liệu có sẵn và xác định điểm mà đường thẳng dự đoán sẽ giao cắt với trục y.
Ví dụ, nếu bạn có một tập hợp các điểm dữ liệu (known_x’s và known_y’s) và bạn muốn tính toán điểm giao cắt của đường thẳng dự đoán, bạn có thể sử dụng hàm INTERCEPT như sau:
$$text{INTERCEPT}(known_y’s, known_x’s)$$
Hàm này sẽ trả về giá trị của điểm giao cắt của đường thẳng với trục y dựa trên dữ liệu bạn cung cấp.
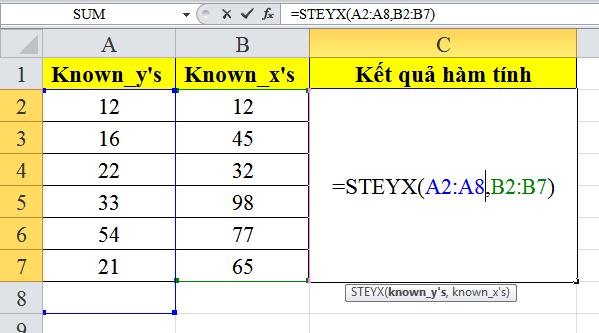
- Hàm STEYX
Hàm STEYX là một hàm trong ngôn ngữ lập trình thống kê, thường được sử dụng để tính sai số chuẩn của giá trị y dự đoán cho mỗi giá trị x trong mô hình hồi quy tuyến tính. Sai số chuẩn này thể hiện mức độ lỗi dự đoán của mô hình so với các điểm dữ liệu thực tế.
Công thức toán học của hàm STEYX có thể được biểu diễn như sau:
$$text{STEYX}(known_y’s, known_x’s)$$
Trong đó:
– **known_y’s**: Mảng các giá trị y đã biết (giá trị của biến phụ thuộc).
– **known_x’s**: Mảng các giá trị x tương ứng đã biết (giá trị của biến độc lập).
Hàm STEYX sử dụng các điểm đã biết để tính toán sai số chuẩn của giá trị y dự đoán cho mỗi giá trị x trong mô hình hồi quy tuyến tính. Nó thường được sử dụng để đo lường mức độ biến thiên giữa các dự đoán của mô hình và các giá trị thực tế tương ứng.
Ví dụ, nếu bạn có một tập hợp các điểm dữ liệu (known_x’s và known_y’s) và bạn muốn tính sai số chuẩn của giá trị y dự đoán cho mỗi giá trị x trong mô hình hồi quy tuyến tính, bạn có thể sử dụng hàm STEYX như sau:
$$text{STEYX}(known_y’s, known_x’s)$$
Hàm này sẽ trả về giá trị sai số chuẩn thể hiện mức độ biến thiên giữa các dự đoán của mô hình và các giá trị thực tế tương ứng.
FAQ – Giải đáp những thắc mắc liên quan đến cú pháp và chức năng của từng hàm trong nhóm các hàm thống kê trong Excel
1. Hàm COUNT là gì và chức năng của nó là gì?
Hàm COUNT trong Excel dùng để đếm số lượng giá trị số trong một dải dữ liệu. Chức năng của nó giúp bạn nhanh chóng biết được số lượng các số trong một dải dữ liệu cụ thể.
2. Hàm AVERAGE có tác dụng gì và làm thế nào để sử dụng nó?
Hàm AVERAGE trong Excel được sử dụng để tính giá trị trung bình của một dải dữ liệu số. Để sử dụng nó, bạn chỉ cần chọn dải dữ liệu bạn muốn tính trung bình, sau đó sử dụng hàm AVERAGE để tính toán kết quả.
3. Hàm MAX và MIN khác nhau như thế nào và làm thế nào để sử dụng chúng?
Hàm MAX trong Excel được dùng để tìm giá trị lớn nhất trong một dải dữ liệu, trong khi hàm MIN được sử dụng để tìm giá trị nhỏ nhất trong một dải dữ liệu. Để sử dụng chúng, bạn chỉ cần chọn dải dữ liệu tương ứng và sử dụng hàm MAX hoặc MIN để tìm kết quả.
Lời kết
Kết luận, việc hiểu và sử dụng các hàm thống kê trong Excel là rất quan trọng đối với việc xử lý dữ liệu và phân tích. Nhờ cú pháp và chức năng của từng hàm trong nhóm các hàm thống kê trong Excel mà chúng ta có thể tính toán và trực quan hóa dữ liệu một cách hiệu quả.
Bài viết trên đã giới thiệu những hàm thống kê phổ biến trong Excel, giúp người đọc nắm vững và áp dụng vào công việc hàng ngày.aptech Cảm ơn bạn đọc!